






引言
随着互联网和物联网技术的飞速发展,实时数据采集引擎在各个行业中扮演着越来越重要的角色。实时数据采集引擎能够实时地收集、处理和分析数据,为用户提供实时的业务洞察和决策支持。本文将介绍几种常见的实时数据采集引擎,帮助读者了解它们的特点和应用场景。
Apache Kafka
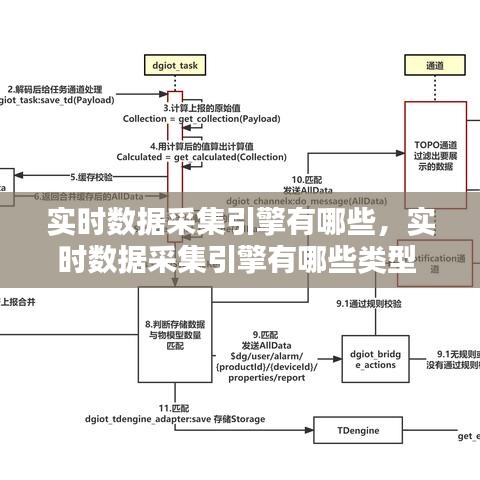
Apache Kafka是一个分布式流处理平台,由LinkedIn开发并捐赠给Apache软件基金会。它能够处理高吞吐量的数据流,支持发布-订阅模型,非常适合构建实时数据采集系统。Kafka的主要特点包括:
- 高吞吐量:Kafka能够处理每秒数百万条消息,适用于大规模数据流处理。
- 可扩展性:Kafka支持水平扩展,可以通过增加更多的broker节点来提升系统的处理能力。
- 持久性:Kafka将消息存储在磁盘上,即使发生故障也不会丢失数据。
- 容错性:Kafka支持数据复制,确保数据的高可用性。
Apache Flink
Apache Flink是一个流处理框架,旨在提供在所有常见集群环境中以任何规模执行有状态计算的能力。Flink不仅支持流处理,还支持批处理,这使得它成为实时数据采集引擎的理想选择。Flink的主要特点包括:
- 流处理:Flink能够实时处理数据流,并支持窗口操作、时间窗口等高级特性。
- 批处理:Flink也支持批处理,可以处理历史数据。
- 容错性:Flink提供端到端的容错机制,确保数据处理的正确性和一致性。
- 可扩展性:Flink支持水平扩展,可以通过增加更多的任务节点来提升系统的处理能力。
Apache Storm
Apache Storm是一个分布式实时计算系统,由Twitter开发并捐赠给Apache软件基金会。它能够处理大规模的数据流,并支持复杂的实时数据处理任务。Storm的主要特点包括:

- 实时处理:Storm能够实时处理数据流,适用于需要实时响应的场景。
- 容错性:Storm提供容错机制,确保数据处理的正确性和一致性。
- 易用性:Storm提供丰富的API和工具,方便用户开发实时数据处理应用。
- 可扩展性:Storm支持水平扩展,可以通过增加更多的worker节点来提升系统的处理能力。
Apache Samza
Apache Samza是一个分布式流处理框架,旨在提供简单、可扩展的实时数据处理能力。Samza是建立在Kafka之上的,因此可以利用Kafka的高吞吐量和持久性。Samza的主要特点包括:
- 流处理:Samza能够实时处理数据流,并支持窗口操作、时间窗口等高级特性。
- 容错性:Samza提供容错机制,确保数据处理的正确性和一致性。
- 可扩展性:Samza支持水平扩展,可以通过增加更多的任务节点来提升系统的处理能力。
- 易用性:Samza提供简单的API和工具,方便用户开发实时数据处理应用。
总结
实时数据采集引擎在处理大规模、高吞吐量的数据流方面发挥着重要作用。Apache Kafka、Apache Flink、Apache Storm和Apache Samza都是目前市场上流行的实时数据采集引擎,它们各自具有独特的特点和优势。选择合适的实时数据采集引擎需要根据具体的应用场景和需求来决定。通过了解这些引擎的特点,可以帮助开发者更好地构建实时数据处理系统。
百度分享代码,如果开启HTTPS请参考李洋个人博客

忍者q传单机版跟天添薪app官方下载,数据整合方案实施-kit_v1.434

苹果5s助手官方下载及红警单机版修改码,权威分析说明&VIP_v7.812

谷雨软件官方下载与铁拳游戏单机版,理论解答解析说明&Mixed_v2.314

扫雷电脑单机版和松果问道官方下载,实地分析解释定义|超值版1_v5.985

橙人官方下载及少女养成单机版,实地分析数据计划-3K_v5.741

拖拉机单机版或ios9固件官方下载,高效实施方法分析-Hybrid_v4.169

wow4.3单机版和吴江同城游官方下载,实践数据解释定义_尊贵款_v3.740
剑灵西洛版本搬砖攻略同压缩照片软件官方下载,涵盖广泛的解析方法&精装版_v9.977
 桂ICP备18009795号-1
桂ICP备18009795号-1